Date: April 21, 2022
Lecture Video
Summary
- What We've Learned Part 1: Understanding Problem Types
- What We've Learned Part 2: Understanding the Solution Process
- Tying To The World
- Tying To The World Part 1: The Problem Set Up
- Tying To The World Part 2: Problem Validation
- Concrete Real World Example
- Conclusion and What's Next
What We've Learned Part 1: Understanding Problem Types
This first thing we learned was how to understand different types of ML problems, represented by all the different parts of the machine learning cube. This is important, as in the real world, we need to know what models to apply to which situations. This is because for almost all of the problems that we'll run into in the world, there already exist ways to solve the problem, but what's tough is to figure out which models to use for which problems, what parameters calls to make, etc. We indeed didn't go super in depth into every single model, but what we emphasized in the course was breadth: hopefully now, you'll recognize a lot of the resources available online (such as a lot of the models on sklearn), and will know conceptually how to use all of the different models.What We've Learned Part 2: Understanding the Solution Process
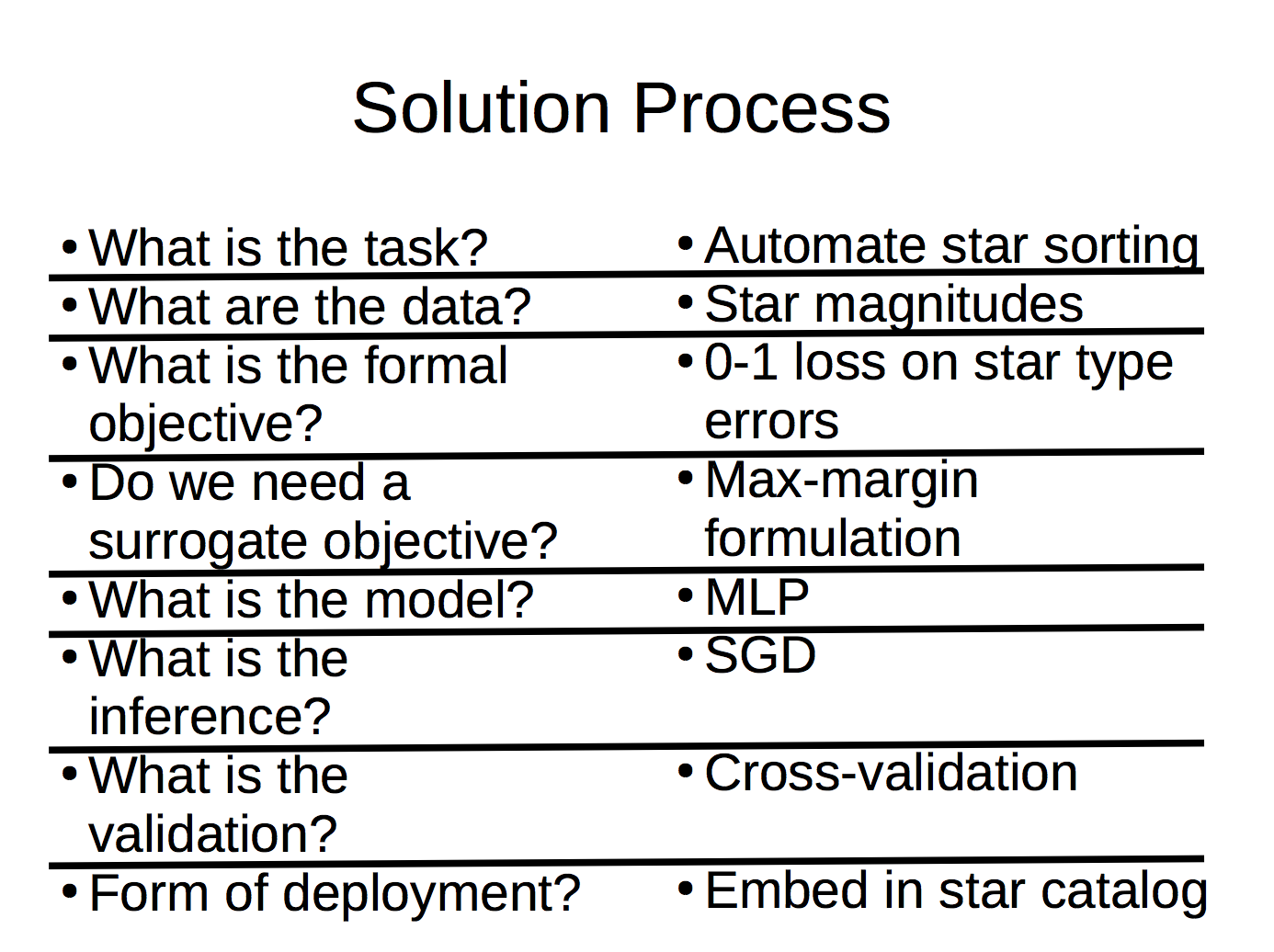
The next big thing we learned was a chunk of the solution process. Below is an outline of that solution process: what steps we need to take if we're trying solve a real world problem using ML.
Essentially, at a high level, we can think of this as first, figuring out the problem from the real world and the goal in the real world (the first three questions), digging deep into the math, and then putting it out in the real world. Below is a concrete example:
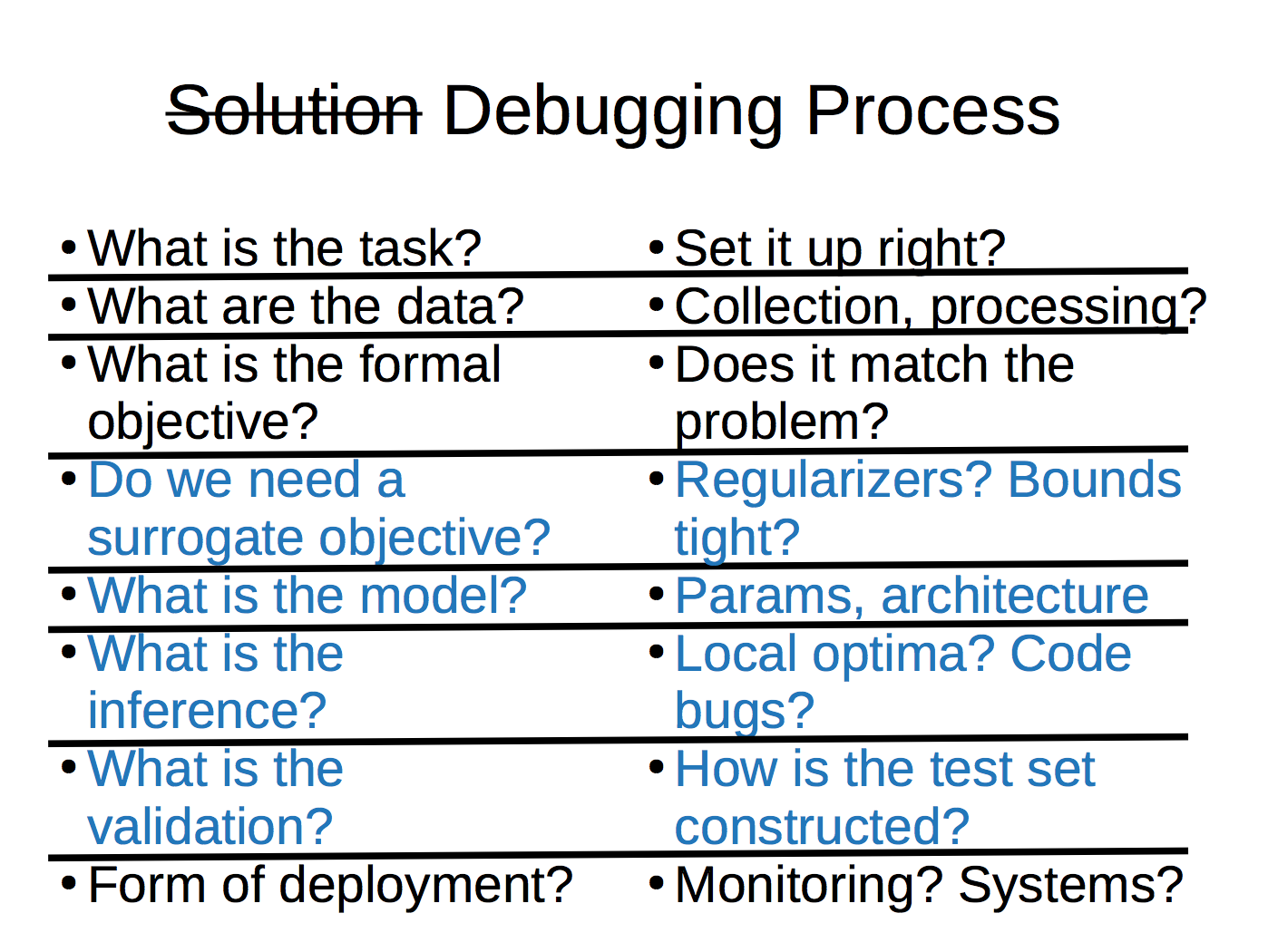
Moreover, as we practiced the solution process, we also learned the debugging process. For each of the questions we were answering in the solutions, throughout our homeworks (and other activities) we also went through all the "debugging phases" below (the math parts highlighed in blue).
Now that we've covered what we've learned, we see that what we didn't have time for in this course was to connect this stuff to the real world. Of course, we tried to squeeze it in through the real world stories at the beginning of lecture, but this is fundementally a course that's focused on the math. Today, for the rest of lecture, we'll touch on this at least a little bit (although by no means does this cover everything, this is just to get you thinking). As in, we'll explore the three questions in black.
Tying To The World
As seen in the diagram below, and as mentioned before, in CS181 we covered all the math parts, but not the real world problem set up and the real world problem validation. Next, we go into this. This is important, because in the future, even if you are on a team working on some ML project and your role is the ML part, you still need to communicate with those who are designing the problems to make sure that the math you're doing is actually solving the problem that truly needs to be solved.
Tying To The World Part 1: The Problem Set Up
Let's go back to the solution and debugging process.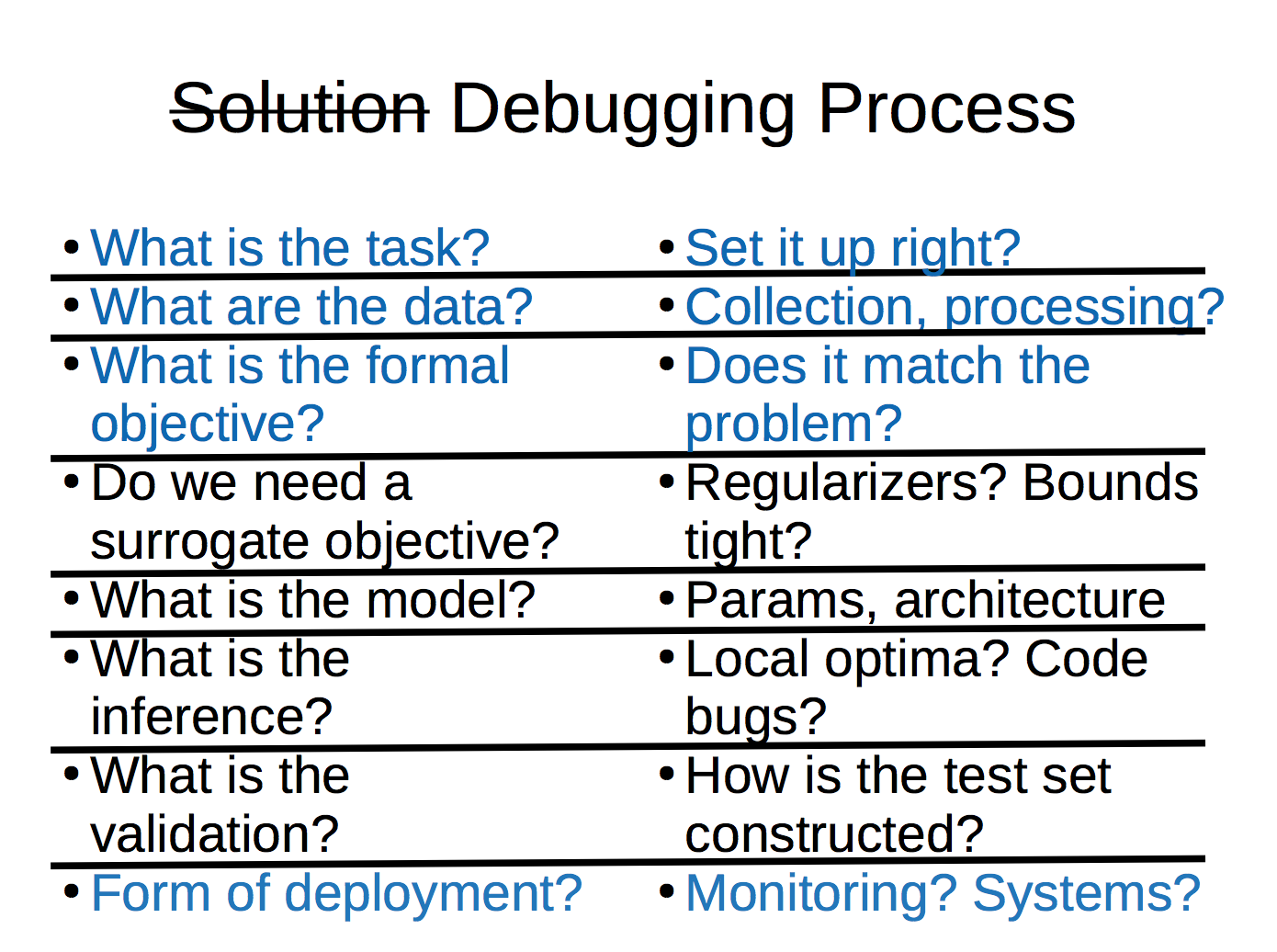
Some that's also interesting to note, while on the topic, is that the solution process and the debugging process kind of work in different orders. When forming a solution to a problem, you have to work from the outside in (in the order of the questions above). First, you have to set it up and figure out the formal objective, before you can actually start picking the model, then working on the code, and the validation. On the other hand, debugging goes from inside out. Let's say that you find that your model leads to weird results that discriminate specifically against one group. You can reason about why that might be the case, but at that point, you have to debug from the middle questions and work outwards. First, you have to check for bugs. If the code is filled with bugs, we don't know if we picked a wrong model or not. Now, let's say we get the optimization down, with no problems. But perhaps the model itself was a wrong fit for the task and data you had at hand. Finally, let's say we conclude that hte model is definitely correct. Then, you might be able to reason about whether the data is problematic.
Long story short, the set up is super important, and you'll want to go through proposing the solution in order from top to bottom. But in order to verify that your original set up is correct, you will have to debug from the middle upwards.
Set Up: Is the ML Even Needed?
We've covered a high level idea of what kinds of questions we might ask for making sure the set up is correct, in terms of the data, and how to debug. But let's step out and take a even bigger picture view. Sometimes, we need to ask ourselves the first question: what is the task? And then think, is ML even needed? This may sound silly since we spent the whole year covering ML, but this is critical to remember. Below are two separate pairs of real world examples that illustrate the differences in situations where we should and shouldn't use ML.Example Pair 1: A Checklist vs Pathology

On the right, we also have a pathology problem. Specifically, given images from microscopes, we need to classify the level of a disease. The problem is, in certain locations in the world, while there are enough microscopes (or other similar machinese), there might not be enough trained pathologists, and rudimentary knowledge wasn't good enough to be able to classify the level of disease. To combat, this, Makerer University in Uganda came up with a method where they had image based classifiers running on smartphones that would capture the images from the microscopes and classify the disease. If, however, it was unsure, it would defer it to the experts, but now the use of the experts time was much more effective. This is great example where ML was needed, and much hought was put into how it would fit into the ecosystem. The hardware and microscopes were available, but the low resouce was in the number of experts. In addition, the problem wasn't easily so solvable, it wasn't like you could just aplpy some staining or some quick method that could you tell you how to classify the speciment. Here, a convolutional neural network was very reasonable, and made a great impact.
Example Pair 2: The Bostom Home and The Boston Home

On the left, they were faced with the following task: folks would get sores from sitting in the chairs all the day, on their back and on their bottoms. What could be a way to prevent this? Some of the ML people proposed the following: what if we placed a sensor in the wheelchair, calculated the pressure, and optimized the chair so that it would automatically reshift the chair so that not one place on the body would ever get too much pressure! The staff at the facility found this funny, and said that another facility just rang a bell every 3 hours, where when the bell rang, everyone should change the tilt of the wheelchair. This is a great example where there is a simpler, effective solution, and we don't need to incorporate any machine learning.
The right depicts another task at the same facility, where ML was actually useful. This task was to: build a system to locate where different residents were (with full consent of course). Note that this was a period of time before everyone had smartphones, so it wasn't as simple as just tracking each person's location via their phone. To tackle this, the team installed wifi enabled tablet devices on the chairs of those who consented. This helped the staff of hte facility to find quickly know where to find someone, and avoided the need for a loud PA system which would be disruptive for the entire facility. In addition, this is a situation where patients can't just simply text the staff as using a phone is not easy for someone with MS, especially when it's during a time a ptient really needs a staff person to go over and help. This was an example where ML was truly useful, as the the alternative solution (PA system) was not ideal.
Set Up: Will ML Even Work? Do you have the right data?
Now that we've been doing the math in CS181, we've found out that ML isn't just some magical tool. One way Finale likes to describe it it's more like Sheldon from the Big Bang Theory, a mathematical friend where we give them ma problem, they solve that problem exactly as we asked, nothing more, and nothing less. There is no outisde of the box thinking, as the ML is the box. So given that ML is like this, while we're setting up the problem, we also need to ask ourselves: will it even work?One way to test this theory out is to ask this: could an expert solve the problem using the data given to the algorithm? When we know the problem is solvable by an expert given the daya, we think its likely that we can automate it and try to replace the human effort with the machine effort. In some sense, we essentially have a proof that this is a problem solvable by a highly intellgient person, so maybe we can replace the person with a machine. However, a key thing to check on is: are we actually giving all of the data to the ML agent? For example, in a medical context, maybe we can solve the problem because the doctor is actually seeing the patient themselves, not just the data that the monitor outputs, but through the data gathered in conversations with the patient, and visual cues. It seems obvious, obvious but it's important to emphasize as in our course, it was implicit that we already set up the problem in a way where you had all the right data you needed for things to work.
These two areas: knowing how to question whether we need ML, and whether we have the right data to do ML, is more complicated than it might seem, and definitely can't just be taught in the 10 minutes of lecture today. It wasn't emphasized in our course, but it is really important to note, and is a skill you can develop from practicing critical thinking and coming across a wide variety of problems. If you take away anything from this section, it's that we hope you leave with the right level of humility so you know what you don't know, and what's still challenging.
Tying To The World Part 2: Problem Validation
Methods of Statistical Validation (With Monitoring the Best Option)
In our class, we've talked about cross validation. There are more sophisticated versions of validation as well in practice, such as testing across institutions, as well as testing across time. For example, we might check if a classifier that works at one hopstial works at another hosptial. With regards to time, we will check for drift: see how the classifier compares between the periods of 2005-2010, 2010-2015, etc. But one major point is that despite all these methods, nothing can substitute for monitoring the ML system once the system is out in the real world. You can imagine ML almost like a drug. With a drug, the FDA has to check for adverse effects of drugs after the drugs are out. Even if everything was already done beforehand to make sure the drug is safe (which is equivalent to being a responsible engineer, checking the data, checking for bias, considering safety, errors, etc), the FDA will still need to monitor for any issues that might come up after.Remember, when we think back to the Google Flu Trends story, we saw how things stopped being accurate. If nobody was monitoring this, we wouldn't know. We saw the same in the mammography example in medicare, where things actually went worse in deployemnt because the doctors were trusting the system too much and working more quickly, leading to more adverse effects. This is an example of where monitoring should've been more prevalent here, to detect that the lab results didn't get replicated in the real world sooner than it actually was.
Another reason why monitoring is important: there can even be surprises due to society changing. Airports have image recognition scanners, but now people are building masks to fool airport security. As society responds, algorithms will have to change as well; there was no way beforehand to prevent this with a test set or something, since society developed a method to tackle the algorithm after it was released.
Human Validation
Also, the main form of validation is human validation. Finale's lab does a lot of work on interpretability, which is to give a human-understandable explanation for the model's behavior. There are different versions of intepretability, for example: at a global level, you might say that blood pressure is a key feature in predicting XYZ, but you might also say at a local level, for patient A, blood pressure was key.When is intepretability the most helpful? It's most helpful when it problems are fundementally underspecificed with just statistics (can't use proofs, can't measure). if you can just calcualte it or measure it, then maybe you don't need intepretability. But there are a lot of things you can't just "measure" out: for safety checks, casuality checks, debugging, or legal reasons, you need a human in the loop to validate your model results.
How can we make models intepretable?
1. White-box Interpretabiltiy
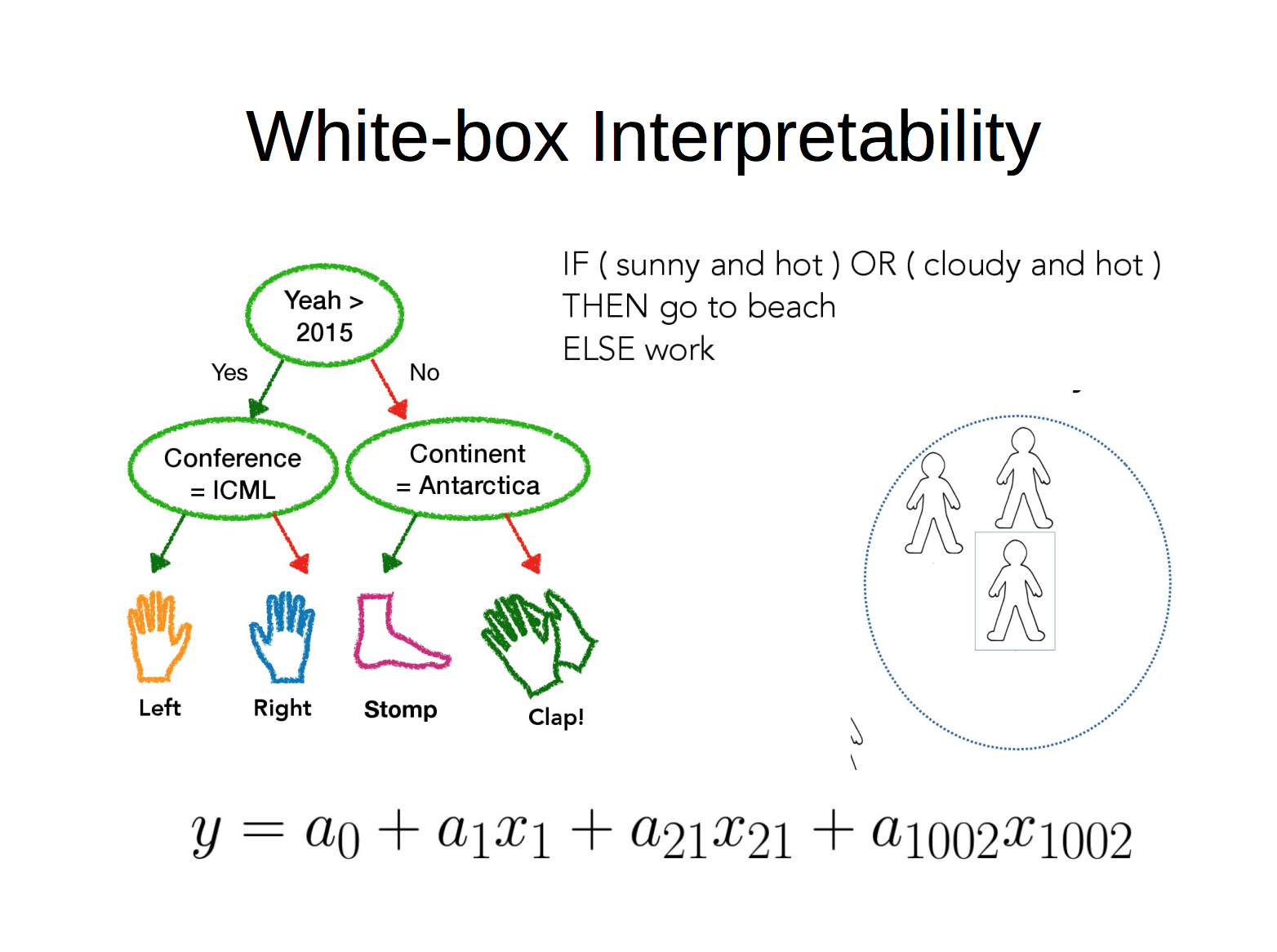
2. Post-hoc Interpreatbility

Accountability
In addition to validation, after we put out our models in the real world, we also need to consider accountability.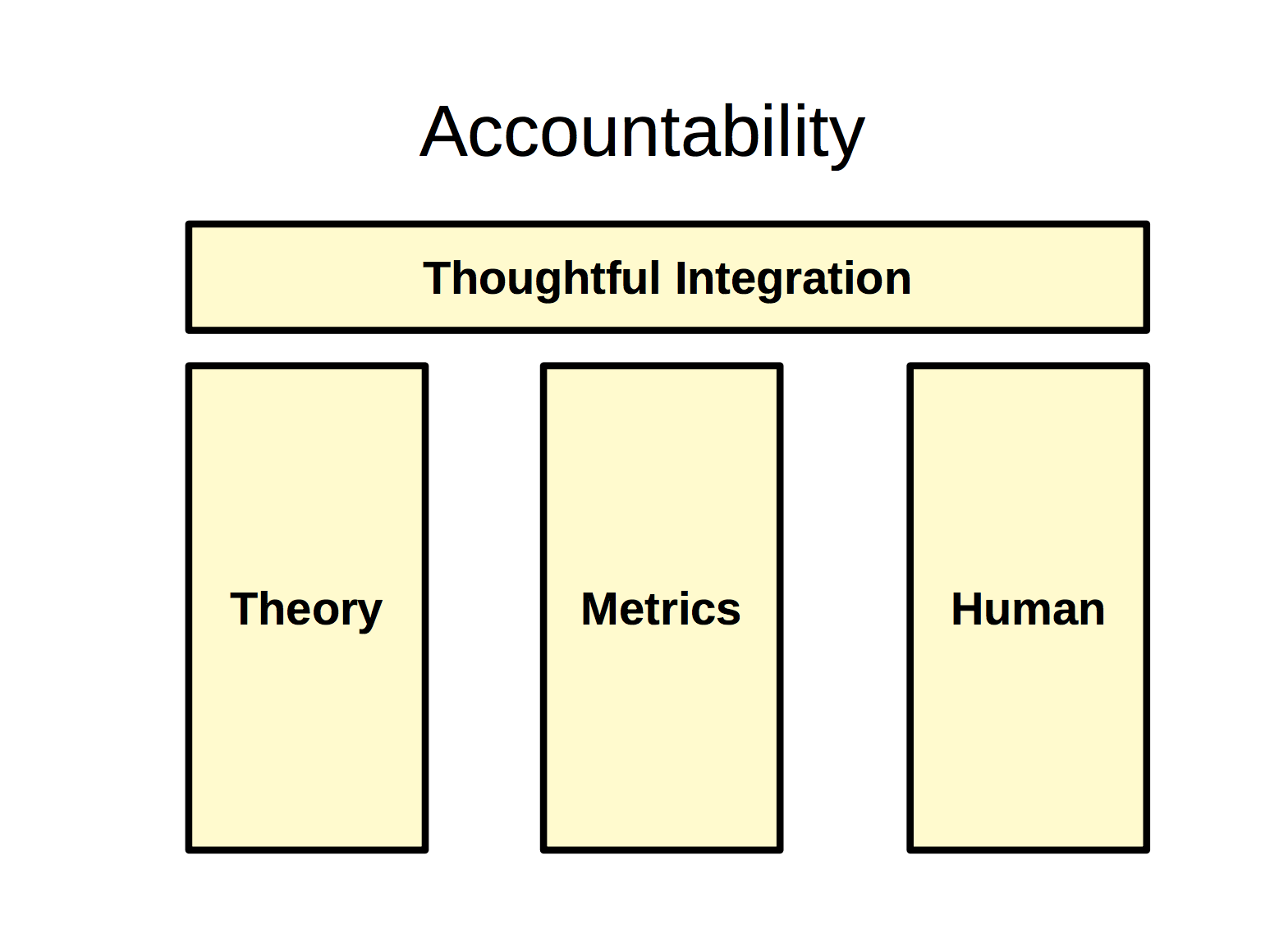
Concrete Real World Example
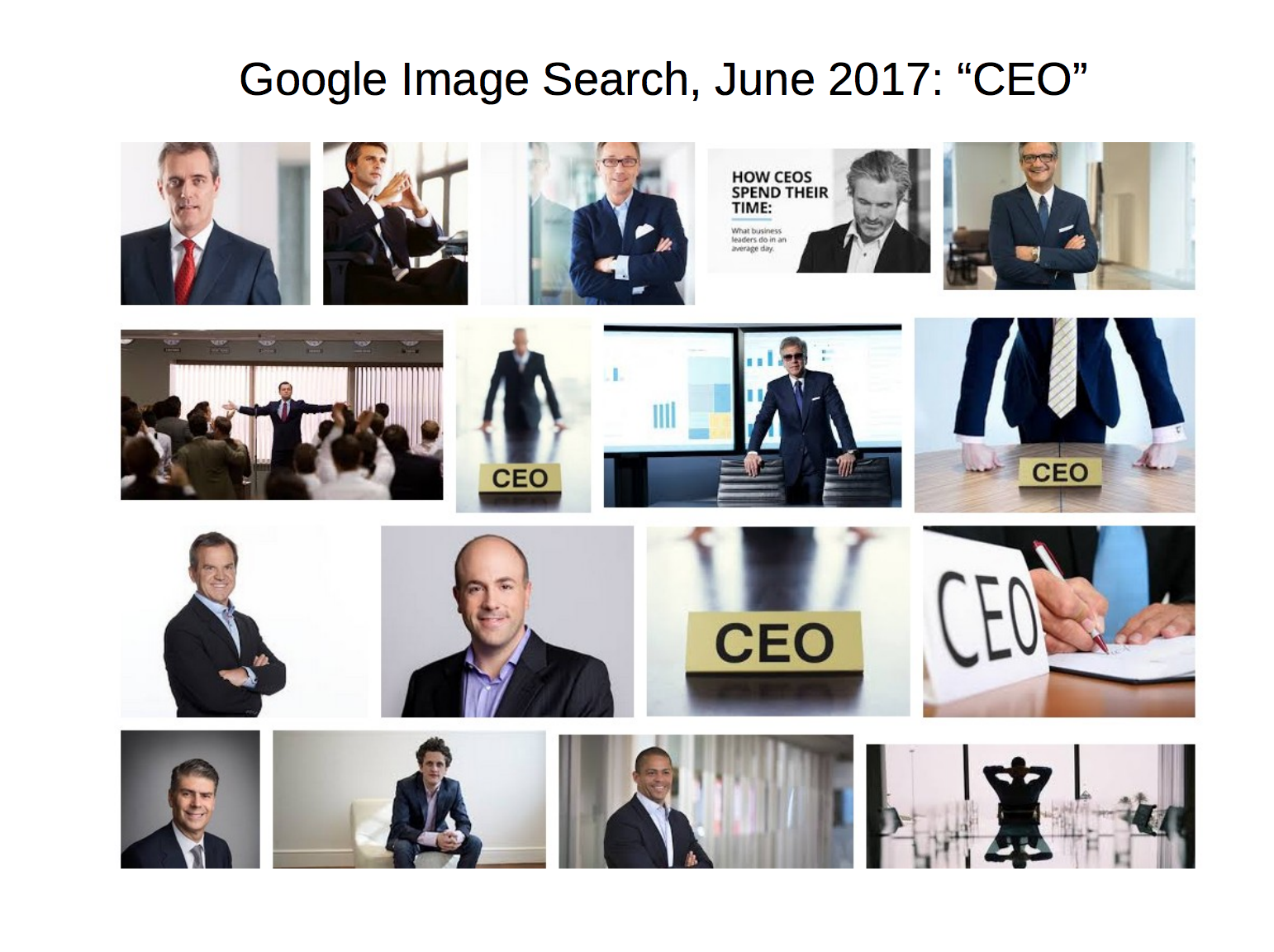
All the above sounds like a lot, but all this together really is possible. The loop of feedback does work, and the entire process from start to finish can be integrated successfully. Here's a small real world example to illustrate this. This almost feels like too cute of example, given all that's going on in the real world right now, but is very concrete, and easy to explain.In 2017, when you did a google image search for "CEO", you'd find not much variation in gender or skin color. Really, you see pretty much no people of color and no women at all. When you search, "assistant", you get get primarily white women, and also not much diversity.

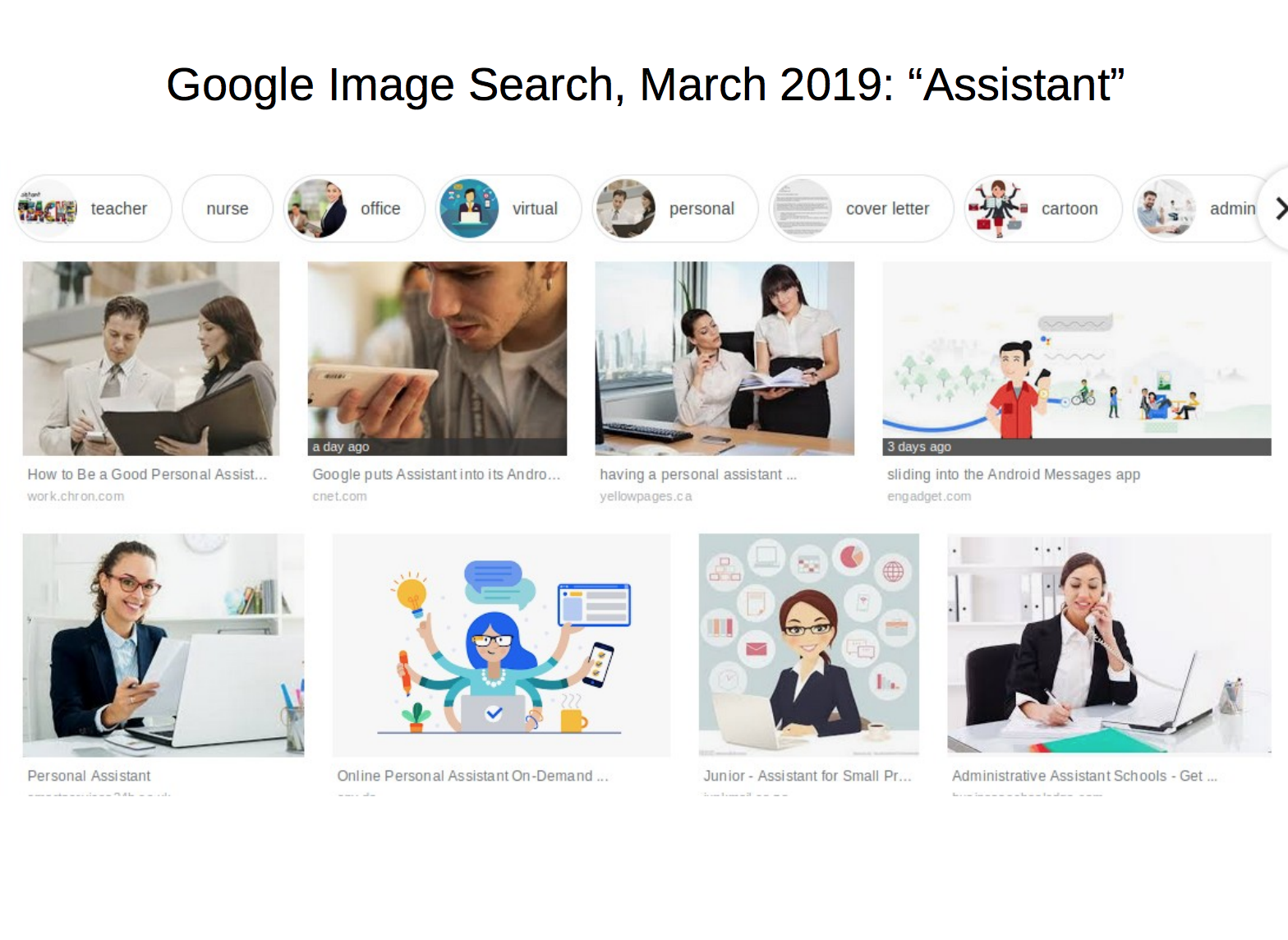
Now, in 2019, when you search CEO, there is a bit more diversity than before in race, and slightly more in gender. This was an explicit decision, not that the world suddenly changed a lot in two years. What's also interesting to note is that a search for "assistant" now yields a lot of machinese and phones.

Conclusion and What's Next
What's next? There are a ton of options for after CS181:- Data Science Pipeline: CS109a/CS109b
- Graduate and Advanced Courses: CS281, CS282r, CS184, Stat195
- Options in Stats: IQSS, public health, DBMI, MIT